目录
理念
时间复杂度
大小比较
$O(1)<O(log_n)<O(\sqrt n)<O(n)<O(nlog_n)<O(n^2)<O(n^3)<O(2^n)<O(n!)$
实际运用
| 输入大小 | 时间复杂度 |
|---|---|
贪心
| 特点 | 说明 |
|---|---|
| 核心策略 | 每一步都选择当前状态下的局部最优解 |
| 目标 | 希望通过局部最优解的累积达到全局最优解 |
| 效率 | 通常非常高效,时间复杂度较低 |
| 回溯 | 不做回溯,一旦选择就不再改变 |
| 全局最优保证 | 不保证总能得到全局最优解,取决于问题和贪心策略的选择 |
| 使用条件 | 需要具有贪心选择性质和最优子结构的问题 |
算法
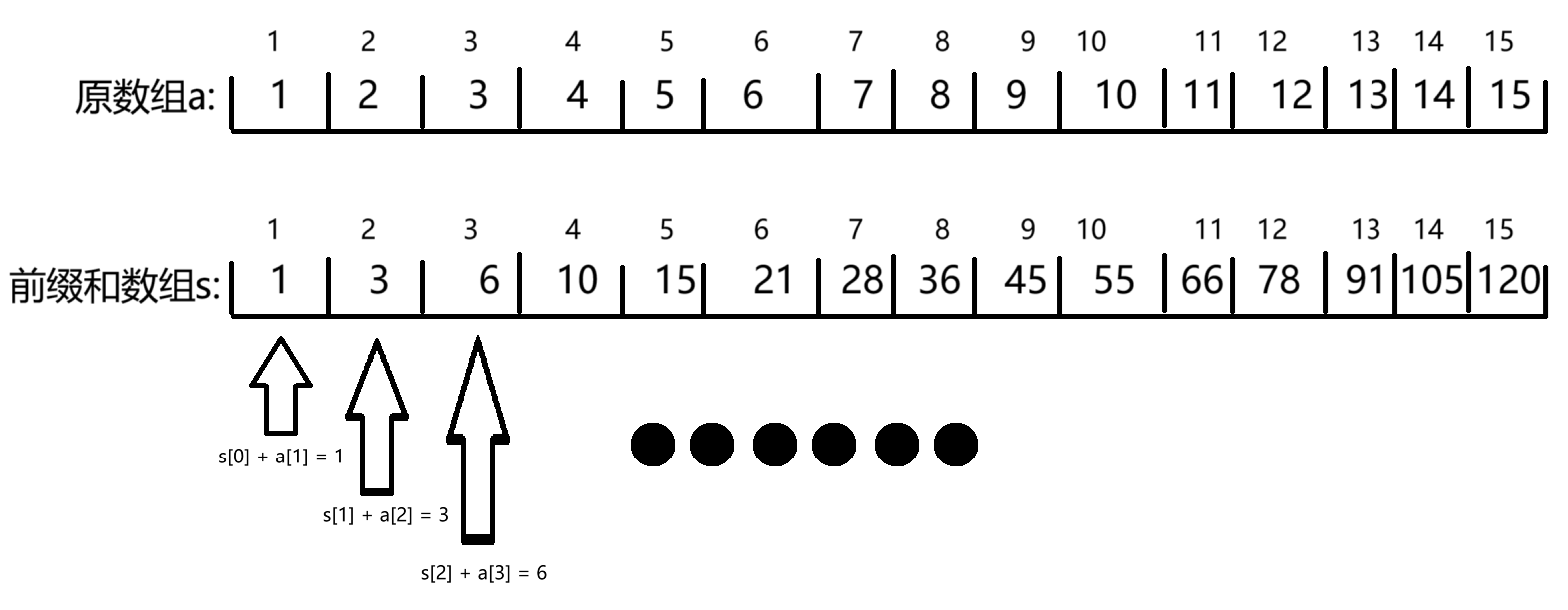
前缀和
用途:可以快速求一段连续区间的和
s[i]=s[i-1]+a[i]//预处理前缀和
s[l-r]的和=s[r]-s[l-1]
二分
基本模板
int f(vector<int>& nums, int target) {
int left = 0, right = nums.size() - 1;
while (left <= right) {
int mid = left + (right - left) / 2; // 防溢出
if (nums[mid] == target) return mid;
else if (nums[mid] < target) left = mid + 1;
else right = mid - 1;
}
return -1; // 未找到
}
- 需确保输入数组有序
- 时间复杂度:O(log n)
标准库函数
| 函数 | 功能 | 实例用法 |
|---|---|---|
| binary_search | 判断目标是否存在 | bool f = binary_search(v.begin(), v.end(), target); |
| lower_bound | 返回第一个 ≥ target 的迭代器 | auto it = lower_bound(v.begin(), v.end(), target); |
| upper_bound | 返回第一个 > target 的迭代器 | auto it = upper_bound(v.begin(), v.end(), target); |
变种
左边界
int left(vector<int>& nums, int target) {
int left = 0, right = nums.size();
while (left < right) {
int mid = left + (right - left) / 2;
if (nums[mid] >= target) right = mid;
else left = mid + 1;
}
return (left < nums.size() && nums[left] == target) ? left : -1;
}
右边界
int right(vector<int>& nums, int target) {
int left = 0, right = nums.size();
while (left < right) {
int mid = left + (right - left) / 2;
if (nums[mid] > target) right = mid;
else left = mid + 1;
}
return (left > 0 && nums[left-1] == target) ? left-1 : -1;
}
搜索
dfs深度优先搜索
基本模板
void dfs(int node, vector<vector<int>>& graph, vector<bool>& visited) {
visited[node] = true;
for (int n : graph[node]) {
if (!visited[n]) {
dfs(n, graph, visited); // 递归探索邻居
}
}
}
应用场景
- 回溯问题
bool findPathDFS(int current, int target, vector<vector<int>>&graph,vector<bool>&visited, vector<int>& path){
visited[current] = true;
path.push_back(current)
if (current == target) return true;
for (int neighbor : graph[current]) {
if (!visited[neighbor]) {
if (findPathDFS(neighbor, target, graph, visited, path))
return true;
}
}
path.pop_back(); // 回溯
return false;
}
- 路径查找
bool findPathDFS(int current, int target, vector<vector<int>>& graph,
vector<bool>& visited, vector<int>& path) {
visited[current] = true;
path.push_back(current);
if (current == target) return true;
for (int neighbor : graph[current]) {
if (!visited[neighbor]) {
if (findPathDFS(neighbor, target, graph, visited, path))
return true;
}
}
path.pop_back(); // 回溯
return false;
}
bfs广度优先搜索
基本模板
void bfs(vector<vector<int>>& graph, int start) {
vector<bool> visited(graph.size(), false);
queue<int> q;
q.push(start);
visited[start] = true;
while (!q.empty()) {
int node = q.front();
q.pop();
// 处理当前节点(如打印或检查目标)
for (int neighbor : graph[node]) {
if (!visited[neighbor]) {
visited[neighbor] = true;
q.push(neighbor);
}
}
}
}
DFS vs BFS
| 特性 | DFS | BFS |
|---|---|---|
| 数据结构 | 栈 | 队列 |
| 探索顺序 | 深度优先 | 广度优先 |
| 空间占用 | O(h)(h为最大深度) | O(w)(w为最大宽度) |
| 最短路径 | 不保证 | 保证(未加权图) |
| 使用场景 | 拓扑排序、连通分量、回溯问题 | 最短路径、层级遍历 |
结构
vectcor动态数组
创建
vector<类型> 名字;
vector<int> v; // 创建一个int类型一维的空动态数组
vector<int> v(n,x); // 创建一个int类型一维动态数组,初始长度n,值为x。
vector<int> v[N]; // 创建一个int类型二维的动态数组,其中一维长度为N,二维长度可变
vector<vector<int>> v(n,vector<int>(m,x)) // 创建一个int类型n行m列的二维动态数组,初始值为x
操作
vector<int> v;
v.push_back(x); // 把元素x添加到末尾
v.pop_back(); // 把末尾元素删除
v.size(); // 返回长度
v[i]; // 获取下标为 i 的元素
v.front(); // 获取首位元素,也可以使用下标 v[0]
v.back(); // 获取末尾元素,也可以使用下标 v[v.size()-1]
v.clear(); // 清空容器
v.begin(); // 返回一个迭代器,指向容器的第一个元素
v.end(); // 返回一个迭代器,指向容器的最后一个元素的后一位
v.erase(v.begin()+1, v.begin()+4); // 删除容器中下标 1~4 的元素,删除的时间复杂度是O(n)
进出
(1) 往空数组添加元素
vector<int> v;
for (int i = 0; i < n; i++)
{
int x; cin >> x;
v.push_back(x); // 通过push_back往末尾添加n个数
}
(2) 提前声明数组大小,可以类似普通数组用下标输入
vector<int> v(n+1); // n+1是为了从1号下标开始存数据
for (int i = 1; i <= n; i++) cin >> v[i];
(3) 循环输出vector的元素
for (int i = 0; i < v.size(); i++) cout << v[i];
(4) 枚举型遍历
for (auto it : v) cout << it;
(5) 排序vector
sort(v.begin(), v.end())
(6) 对vector排序并去重
sort(v.begin(), v.end());
v.erase(unique(v.begin(), v.end()), v.end()); // unique函数必须先排序才能起到去重效果
stack栈
创建
#include<stack>
stack<int> stk; // 创建int类型栈,名字为stk
操作
stk.top() // 查看栈顶元素
stk.size() // 返回栈内元素个数
stk.empty() // 返回栈是否为空
进出
stk.push(x) // 把x压栈
stk.pop() // 弹出栈顶元素
queue队列
创建
#include<queue>
queue<int> q;
操作
q.front(); // 查看队头
q.back(); // 查看队尾
q.size(); // 查看q元素个数
q.empty(); // 查看q是否为空
进出
q.push(x); // 队尾插入x
q.pop(); // 弹出队头
priority_queue优先队列
性质
元素被赋予优先级权重,优先级最高的元素始终位于队列前端。出队顺序完全由优先级决定,与元素插入时间无关。
set和unordered_set集合
创建
set<类型> 名字;
操作
s.erase(x) //删除值为 x 的所有元素,返回删除元素的个数。
s.clear() //清空 set。
s.count(x) //返回 set 内键为 x 的元素数量。
s.find(x) //在 set 内存在键为 x 的元素时会返回该元素的迭代器,否则返回 end()。
s.empty() //返回容器是否为空。
s.size() //返回容器内元素个数。
进出
set<int> s;
s.insert(x);//当容器中没有等价元素的时候,将元素 x 插入到 set 中。
//迭代器输出
for (auto it:s)
cout << it << " ";
for (auto it = s.begin(); it!=s.end(); it++)
cout << *it << " ";
unordered_set 用法类似,只不过不会排序,所以插入、查找、删除的时间复杂度均为O(1)。
map和unordered_map哈希表
创建
map<类型, 类型> 名字;
比如要存储学生的名字和对应成绩,可以创建map<string, int> score;
操作
map<int,int> mp;
mp[3] = 5; // 通过赋值创建一个键值对映射
mp[4] = 2;
mp[2] = 7;
mp.erase(4); // 删除{4,2}这个键值对
cout << mp.count(2); // 输出1,表示2这个键存在
cout << mp.count(5); // 输出0,表示5这个键不存在
// 枚举型遍历访问map的所有键值对
for (auto it : mp)
{
cout << it.first << " " << it.second << endl;
}
unordered_map 【哈希表】的基础用法和map一样,只不过它不会自动排序,所以访问速度更快。
数学
排列组合
排列(有顺序)
在n里面选择m个:
组合(无顺序)
在n里面选择m个:
其他
位运算
与、或、异或
| 运算 | 运算符 | 解释 |
|---|---|---|
| 与 | & | 只有两个对应位都为1时才为1 |
| 或 | 丨 | 只要两个对应位中有一个1时就为1 |
| 异或 | ^ | 只有两个对应位不同时才为1 |
取反
把一个数的二进制补码中的0和1全部取反(0变为1,1变为0)。有符号整数的符号位在 ~ 运算中同样会取反。 补码:在二进制表示下,正数和0的补码为其本身,负数的补码是将其对应正数按位取反后加一。
左右移
num<<i表示将num的二进制表示向左移动i位所得的值。
num>>i表示将num的二进制表示向右移动i位所得的值。
模板
int mulPowerOfTwo(int n, int m) { // 计算 n*(2^m)
return n << m;
}
int divPowerOfTwo(int n, int m) { // 计算 n/(2^m)
return n >> m;
}
快速幂
概述
给定形式,即表示将𝑛的前𝑡−𝑖+1位二进制位当作一个二进制数,则有如下变换:
$$\begin{aligned} n &= n_{t\dots 0} \\ &= 2\times n_{t\dots 1} + n_0\\ &= 2\times (2\times n_{t\dots 2} + n_1) + n_0 \\ &\cdots \end{aligned}$$那么有:
$$\begin{aligned} a^n &= a^{n_{t\dots 0}} \\ &= a^{2\times n_{t\dots 1} + n_0} = \left(a^{n_{t\dots 1}}\right)^2 a^{n_0} \\ &= \left(a^{2\times n_{t\dots 2} + n_1}\right)^2 a^{n_0} = \left(\left(a^{n_{t\dots 2}}\right)^2 a^{n_1}\right)^2 a^{n_0} \\ &\cdots \end{aligned}$$模板
#include<bits/stdc++.h>
using namespace std;
int main(){
long long a,b,p;
cin>>a>>b>>p;
long long ans=1;
while(b>0){
if(b&1) ans=ans*a%p;
a=a*a%p;
b>>=1;
}
cout<<ans;
return 0;
}
质数与约数
质数
判断()
bool is_prime(int n) {
if (n < 2) return 0;
for (int i=2; i<=n/i; i++) { // 写 i<=sqrt(n)也可以,但是还需要算,比较慢。
if (n%i == 0) return 0;
}
return 1;
}
分解
void divide(int n) {
// 对数字 n 进行分解质因数
for (int i=2; i<=n-1; i++) {
if (n%i == 0) {
int cnt = 0;
while (n%i == 0) {
n /= i;
cnt++;
}
printf("%d %d\n", i, cnt);
}
}
}
质数筛(3)
朴素筛
const int N = 1e6+5;
int primes[N], cnt; // primes用来存储质数,cnt是对应数组的下标
bool st[N]; // st[i]标记数字是否被筛掉
void get_primes(int n) {
// 筛选 2~n中的所有质数
for (int i=2; i<=n; i++) {
if (!st[i]) {
primes[++cnt] = i; // 质数存到数组中
}
for (int j=i+i; j<=n; j+=i) st[j] = 1; // 筛掉数字的倍数
}
// 这样过完之后,所有的质数就存到了primes数组中
// 同时 st 中标记了每个数字是否是质数。
}
埃氏筛
const int N = 1e6+5;
int primes[N], cnt; // primes用来存储质数,cnt是对应数组的下标
bool st[N]; // st[i]标记数字是否被筛掉
void get_primes(int n) {
// 筛选 2~n中的所有质数
for (int i=2; i<=n; i++) {
if (!st[i]) {
primes[++cnt] = i; // 质数存到数组中
for (int j=i+i; j<=n; j+=i) st[j] = 1; // 筛掉质数的倍数
}
}
// 这样过完之后,所有的质数就存到了primes数组中
// 同时 st 中标记了每个数字是否是质数。
}
欧拉筛(线性筛)
void get_primes(int n) {
// 筛选 2~n中的所有质数
for (int i=2; i<=n; i++) {
if (!st[i]) primes[++cnt] = i; // 质数存到数组中
// primes[j] <= n/i 理解为 primes[j]*i <= n,即只筛n范围内的数字
for (int j=1; primes[j]<=n/i; j++) {
st[primes[j]*i] = 1; // 筛掉i的素数倍数
if (i%primes[j] == 0) break; // 线性复杂度的关键
}
}
}
约数
判断()
const int N = 1e5+5;
int res[N], cnt;
void get_divisors(int n) {
for (int i=1; i<=n/i; i++) {
if (n%i == 0) {
res[++cnt] = i;
if (i != n/i) res[++cnt] = n/i; // 这个判断是防止加两次 n/i 进去
}
}
sort(res+1, res+1+cnt); // 如果不要求排序,也可以不用。
// 另外,也可以用两个数组,一个存前半部分一个存后半部分,最后合并,比排序更快。
}