1:以比较作为基本运算,在 𝑁 个数中找出最大数,最坏情况下所需要的最少的比较次数为()。
这题只要考虑最坏情况即可,最坏情况为最大的在最后面
最坏的情况用的次数就是N-1。
2:6个人,两个人组一队,总共组成三队,不区分队伍的编号。不同的组队情况有()种。
公式:C(6,2)×C(4,2)×C(2,2)÷A(3,3)
=(6×5÷2)×(4×3÷2)×(2×1÷2)÷(3×2×1)
=15×6×1÷6
=15
3:以为起点,对下边的无向图进行深度优先遍历,则四个点中有可能作为最后一个遍历到的点的个数为()。
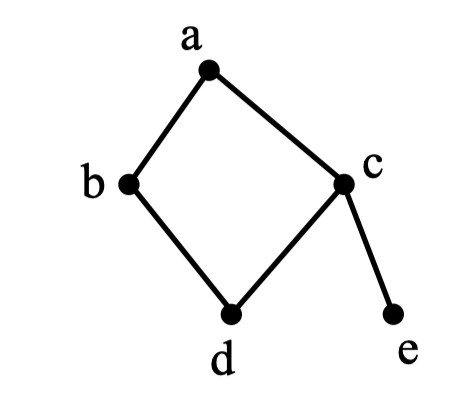
A.1
B.2
C.3
D.4
有两条路径 第一条:a -- b,b -- d,d -- c,c -- e。结果是e
第二条:a -- c,c -- e,e -- c,c -- d,d -- b结果是b
4:阅读程序回答问题
(1):

判断题
输入的 𝑛 等于 1001 时,程序不会发生下标越界()
对 错
分析:a一共有1000个盒子1001>1000,所以会超
输入的 𝑎[𝑖]必须全为正整数,否则程序将陷入死循环()
对 错
这题我们直接看后面的选择题会发现选择题输入了一个负数。
以上为开玩笑的,以下为正题。
输入负数我不知道,但可以输入0呀
当输入为 5 2 11 9 16 10时,输出为3 4 3 17 5。()
对 错
换成二进制一个一个的去算
数字如下:
十进制 二进制
2 10
11 1011
9 1001 16 10000 10 1010
当输入为 1 511998时,输出为18
对 错
换成二进制计算
511998的二进制如下:0111 1100 1111 1111 1110
将源代码中g函数的定义(14∼17行)移到 main 函数的后面,程序可以正常编译运行()
在main函数前没有定义会报错
单选题
当输入为 2 -65536 2147483647`时,输出为( )。
A. 65532 33
B.65552 32
C.65535 34
D.65554 33
因为214783647=2的31次方-1
所以有31个1。
然后最后一位为2
31+2=33
(2):

判断题
输出的第二行一定是由小写字母、大写字母、数字和 +=、 /、= 构成的字符串。()
对 错
可能会有其他字符,比如:空格
可能存在输入不同,但输出的第二行相同的情形。()
对 错
都输入不属于base[64]里的字符输出结果一样
输出的第一行为 -1。()
对 错
我们分析一下可以得知第一行为11111111=-1.
单选题
设输入字符串长度为 𝑛,decode 函数的时间复杂度为()
A. 𝑂(sqrt(𝑛))
B. 𝑂(𝑛)
C. 𝑂(𝑛log𝑛)
D. 𝑂()
一个for循环一次+4
复杂度为:𝑂(𝑛/4)去除常数项=𝑂(𝑛)
当输入为 Y3Nx 时,输出的第二行为()。
A. csp
B. csq
C. CSP
D. Csp
带入算式计算
当输入为Y2NmIDIwMjE= 时,输出的第二行为()。
A. ccf2021
B. ccf2022
C. ccf 2021
D. ccf 2022
一共有8个字符,因为最后有一个'=',排除a,b。
然后算一下E是1还是2。
 假设输入的 𝑥 是不超过1000的自然数,完成下面的判断题和单选题:
假设输入的 𝑥 是不超过1000的自然数,完成下面的判断题和单选题:
判断题
若输入不为 1,把第 13 行删去不会影响输出的结果。()
对 错
因为程序后面没有f[1]和g[1]的地方,所以不影响
第25行的 f[i] / c[i * k]可能存在无法整除而向下取整的情况。()
对 错
不可能,因为c[i*k]永远是f[i]的因数
在执行完init()后,f数组不是单调递增的,但g数组是单调递增的。()
对 错
因为f数组不是,所以g数组也不是是单调的。
单选题
init函数的时间复杂度为( )。
A. 𝑂(n)
B. 𝑂(𝑛log𝑛)
C. 𝑂((𝑛))
D. 𝑂()
还是因为只有一个for循环所有时间复杂度为:𝑂(n)在执行完init()后,𝑓[1],𝑓[2],𝑓[3]…𝑓[100] 中有()个等于 2。
A. 23
B. 24
C. 25
D. 26
换个角度说就是找有多少质数
当输入为 1000 时,输出为()。
A. 15 1340
B. 15 2340
C. 16 2340
D. 16 1340
首先排除A,D。因为1000+500就等于1500了,然后,1000有16个因数。因为1000不是平方数,所以它有偶数个因数。
Josephus 问题
#include<bits/stdc++.h>
using namespace std;
const int MAXN=1000000;
int f[MAXN];//当前位置的人是否出圈,0表示没出,1表示已出
int main()
{
int n;
cin>>n;
int i=0,p=0,c=0;//p:当前报数,c:出圈人数
while(问题1)//如果还有两个以上的人,继续
{
if(f[i]==0)
{
if(问题2)//如果报数是1,出圈
{
f[i]=1;
问题3;//出圈人数更新
}
问题4;//报数状态更新
}
问题5;//考虑下一位置
}
int ans=-1;
for(int i=0;i<n;i++)
{
if(f==0)
{
ans=i;//找到没有出圈的人,记录答案
}
}
cout<<ans<<endl;
return 0;
}
①处应填( ) A.i < n
B.c < n
C.i < n- 1
D.c < n-1
②处应填( ) A.i % 2 == 0
B.i % 2 == 1
C.p
D.!p
③处应填( )
A.i++
B.i = (i + 1) % n
C.c++
D.p ^= 1
④处应填( ) A.i++
B.i = (i + 1) % n
C.c++
D.p ^= 1
⑤处应填( )
A.i++
B.i = (i + 1) % n
C.c++
D.p ^= 1
矩形计数
#include<bits/stdc++.h>
using namespace std;
struct point
{
int x,y,id;
};
bool equals(point a,point,b)
{
return a.x==b.x&&a.y==b.y;
}
bool cmp(point a,point b)
{
问题1;//坐标有序,x小优先,然后y小优先
}
void sort(point A[],int n)
{
for(int i=0;i<n;i++)
{
for(int j=i;j<n;j++)
{
if(cmp(a[j],a[j-1]))
{
point t=A[j];
A[J]=A[J-1];
A[j-1]=t;
}
}
}
}
int unique(point A[],int n)
{
int t=0;
for(int i=0;i<n;i++)
{
if(问题2)//如果去重数组没有坐标,或者最后加入的坐标于当前坐标不一样
{
A[t++]=A[i];
}
}
return t;
}
bool bs(point A[],int n,int x,int y)
{
point p;
p.x=x;
p.y=y;
p.id=n;
int a=0,b=n-1;
while(a<b)
{
int mid=问题3;//中间位置
if(问题4)//如果p比A[]
{
a=mid+1;
}
else
{
b=mid;
}
}
return equals(A[a],p);
}
const int MAXN=1000;
point A[MAXN];
int main()
{
int n;
cin>>n;
for(int i=0;i<n;i++)
{
cin>>A[i].x>>A[i].y;
A[i].id=i;
}
sort(A,n);
n=unique(A,n);
int ans=0;
for(int i=0;i<n;i++)
{
for(int j=0;j<n;j++)
{
if(问题5&&bs(A,n,A[i].x,A[i].y)&&bs(A,n,A[j].x,A[j].y))
{
ans++;
}
}
}
cout<<ans<<endl;
return 0;
}
①处应填 ( ) A. a.x != b.x ? a.x < b.x : a.id < b.id
B. a.x != b.x ? a.x < b.x : a.y < b.y
C. equals(a, b) ? a.id < b.id : a.x < b.x
D. equals(a, b) ? a.id < b.id : (a.x != b.x ? a.x < b.x : a.y < b.y)
②处应填 ( )
A. i == 0 || cmp(A[i], A[i - 1])
B. t == 0 || equals(A[i], A[t - 1])
C. i == 0 || !cmp(A[i], A[i - 1])
D. t == 0 || !equals(A[i], A[t - 1])
③处应填 ( )
A. b - (b - a) / 2 + 1
B. a + b + 1) >> 1
C. (a + b) >> 1
D. a + (b - a + 1) / 2
④处应填 ( )
A. !cmp(A[mid], p)
B. cmp(A[mid], p)
C. cmp(p, A[mid])
D. !cmp(p, A[mid])
⑤处应填 ( ) A. A[i].x == A[j].x
B. A[i].id < A[j].id
C. A[i].x == A[j].x && A[i].id < A[j].id
D. A[i].x < A[j].x && A[i].y < A[j].y
